|
Xinyu Tian I am a PhD student at Australian National University supervised by Prof. Jing Zhang, with research interests in multimodal reasoning and model adaptation. Previously, I received my double Bachelor's degree from Australian National University and Shandong University. I am fortunate to have joined TikTok on leave from my PhD, where I explore video understanding and reasoning with multimodal models, working with Dr. Yongzhi Xu. Before this role, I served as a research intern at CSIRO, where I worked on multi-agent learning and its transfer to real-world scenarios, mentored by Prof. Mahbuba Afrin. Email / CV / Google Scholar |

|
News
|
Publications |
|
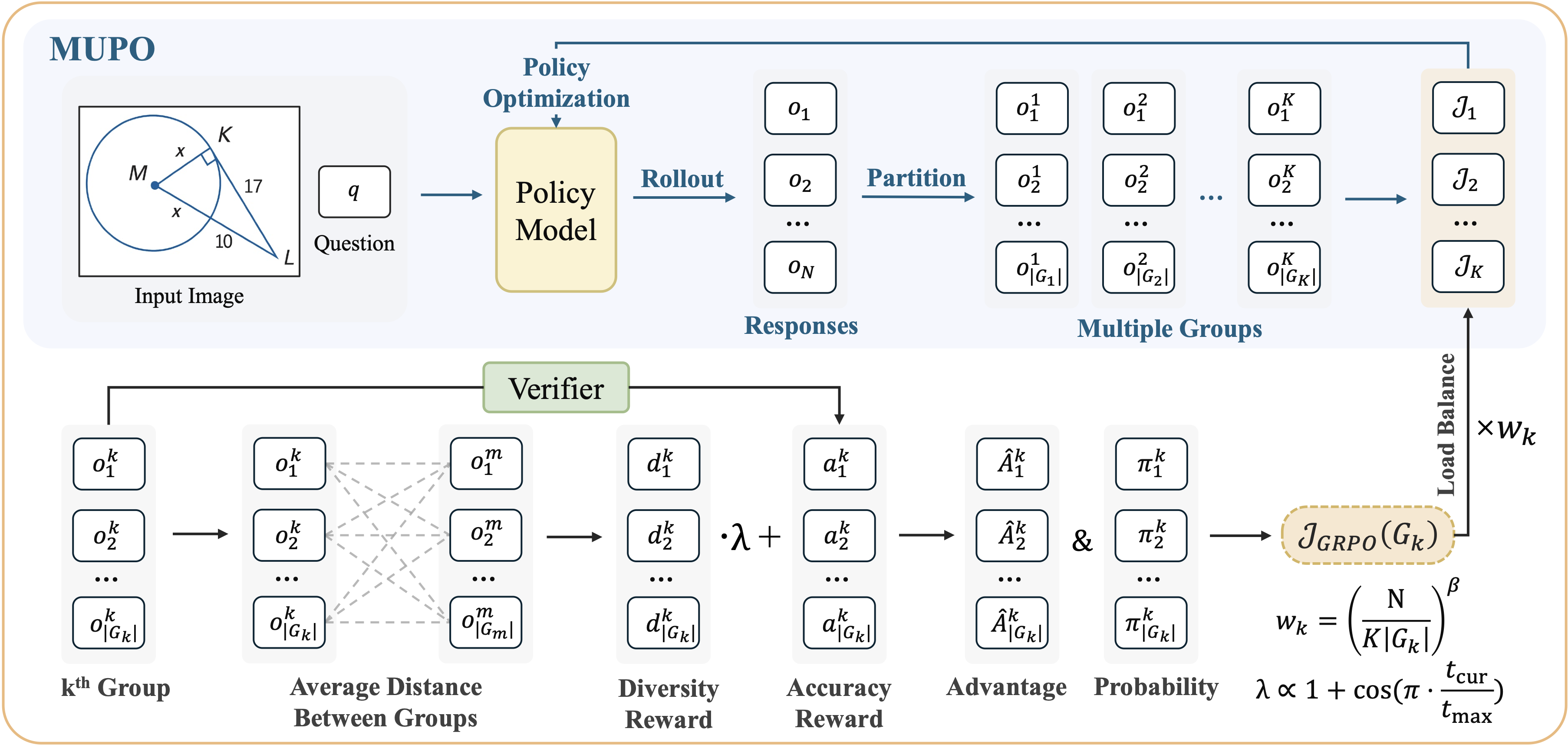
All Roads Lead to Rome: Incentivizing Divergent Thinking in Vision-Language Models
Xinyu Tian, Shu Zou, Zhaoyuan Yang, Mengqi He, Peter Henry Tu, Jing Zhang CVPR, 2026 (Highlight, Top 2.5%) We investigate diversity collapse, a common issue in GRPO models where their thinking is usually limited and lacks diversity. We propose MUPO, which helps VLMs learn to approach the same problem from multiple perspectives. |

|
More Thought, Less Accuracy? On the Dual Nature of Reasoning in Vision-Language Models
Xinyu Tian, Shu Zou, Zhaoyuan Yang, Mengqi He, Fabian Waschkowski, Lukas Wesemann, Peter Henry Tu, Jing Zhang ICLR, 2026 arXiv We find longer reasoning may not lead to better accuracy due to visual forgetting as the reasoning process goes on. We propose VAPO, which encourages VLMs to preserve perception capability during the reasoning process.
|

|
Identifying and Mitigating Position Bias of Multi-image Vision-Language Models
Xinyu Tian, Shu Zou, Zhaoyuan Yang, Jing Zhang CVPR, 2025 (Oral, Top 1%) arXiv We find that VLMs are highly sensitive to image order. We propose SoFA, an inference-time attention rectification method that improves robustness to positional changes.
|
|
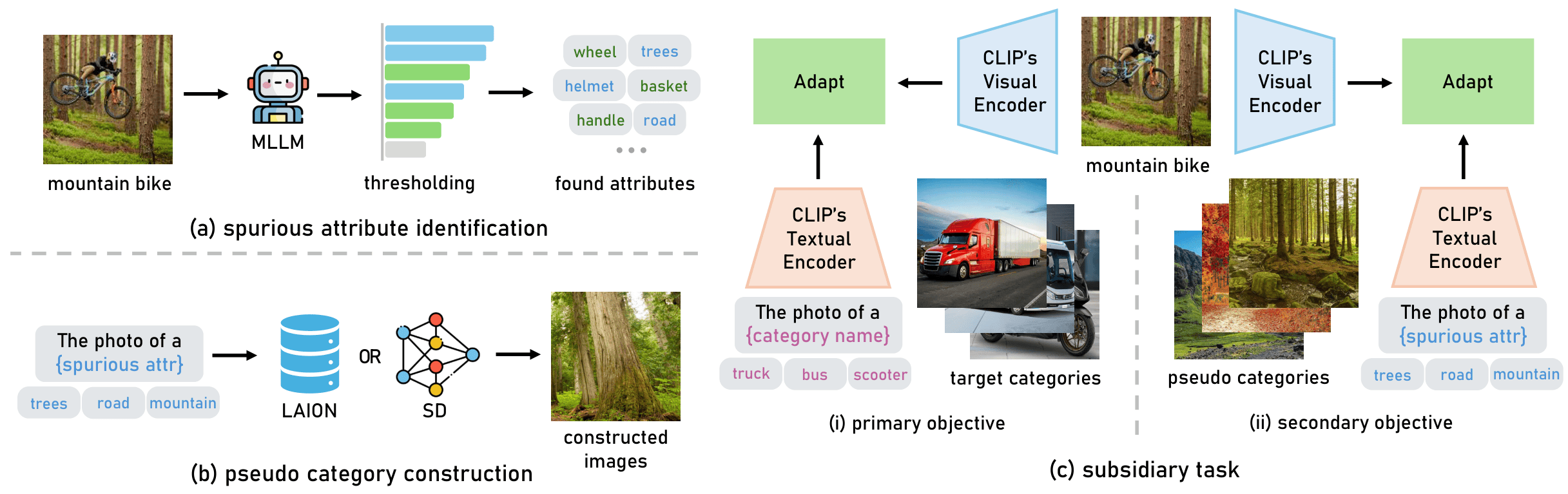
Black Sheep in the Herd: Playing with Spuriously Correlated Attributes for Vision-Language Recognition
Xinyu Tian, Shu Zou, Zhaoyuan Yang, Mengqi He, Jing Zhang ICLR, 2025 arXiv We find that spurious attributes greatly hurt the model robustness. We propose SAP and SAS to detect spurious attributes and mitigate their impact on object recognition
|
|
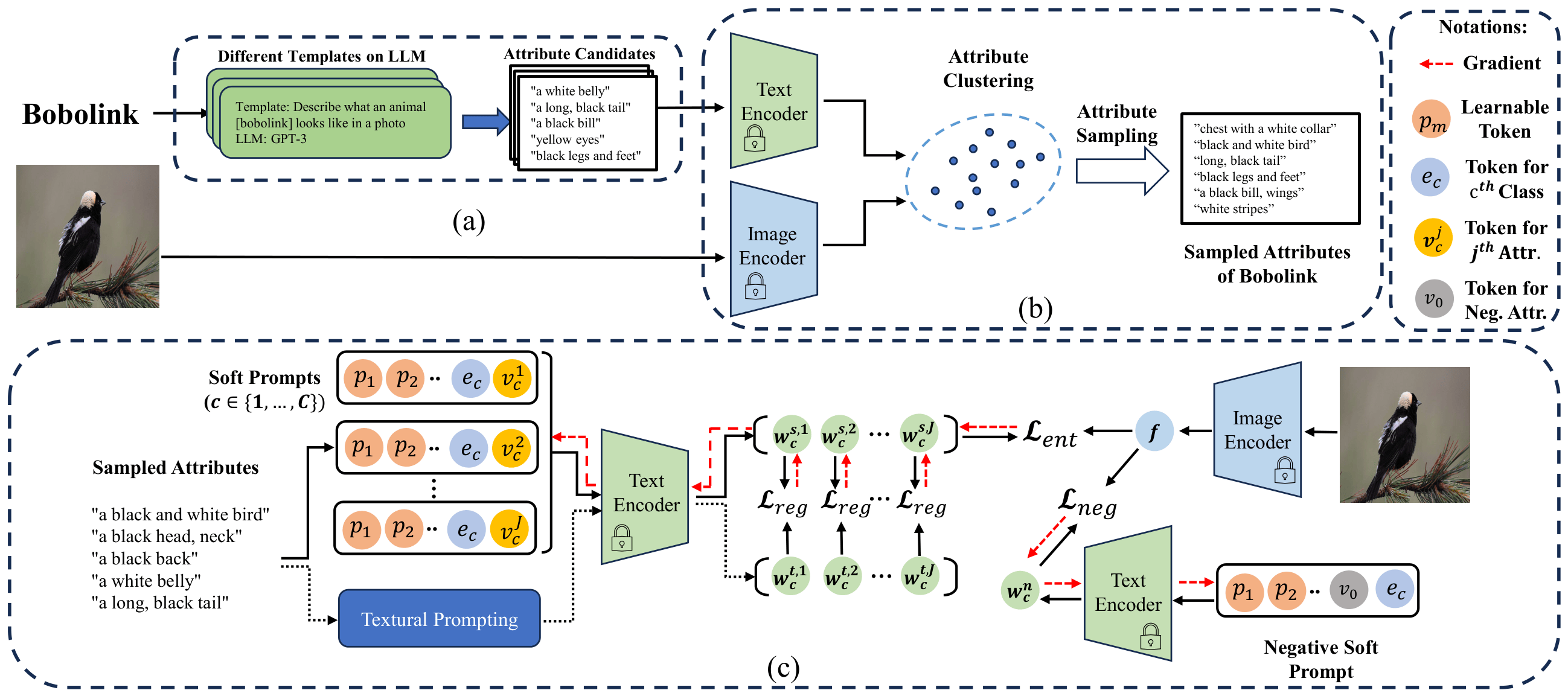
ArGue: Attribute-Guided Prompt Tuning for Vision-Language Models
Xinyu Tian, Shu Zou, Zhaoyuan Yang, Jing Zhang CVPR, 2024 arXiv We propose ArGue, a prompt tuning method to leverage visual attributes for fine-grained vision language recognition, significantly improving accuracy and generalization.
|
|
|